주의: 이 글은 머학원생 척척석사(진)이 그냥 공부하면서 끄적인 내용으로 틀린 내용을 포함할 수 있음
Video depth estimation 방법
- Monocular depth estimation model을 frame 단위로 그냥 이용하는 방법
- 특징: 제곧내
- 장점: 쉽고 단순하고 빠르고
- 단점: 각 frame 별 결과의 scale inconsistency로 인한 flickering 현상 -> 이것 때문에 사실상 사용이 불가
- 예시: 대부분의 monocular depth estimation 모델
- Monocular depth estimation model을 fine-tuning하는 방법
- 특징: 우선 일반적인 monocular depth estimation 모델로 초기 깊이 영상을 구한 후 해당 scene에 대해서 frame별 pose 정보도 구한다. 그리고 이 둘을 이용해 geometrical consistency error를 확인해서 이것을 loss로 monocular depth estimation을 fine-tuning. 결과적으로 해당 장면에 대해서는 scale-consistency가 맞게 된다.
- 장점: 매우 정확한 결과를 얻을 수 있음
- 단점: Fine-tuning을 해야함
- 예시
- Consistent Video Depth Estimation (SIGGRAPH 2020) - SfM 기반 pose
- Robust Consistent Video Depth Estimation (CVPR 2021) - 학습 기반 pose 사용
- Joint depth-(flow)-pose learning 방법
- 특징: 여러 frame을 입력 받아 depth, flow와 pose estimation을 같이 하는 multi-modal(auxiliary-modal?)을 만들고 geometric scale 문제를 고려하면서 학습되도록 하는 방법.
- 장점: 비교적 정확하면서 복잡한 SfM이나 별도의 최적화 없이 바로 consistent한 depth와 추가적인 정보(pose, flow)들을 한 번에 구할 수 있음
- 단점: 최적화 방법보다는 당연히 성능이 떨어짐 (그리고 다른 문제가 있는지는 더 확인해서 추후 업데이트)
Joint depth-(flow)-pose learning (two-view geometry)
- Unsupervised Learning of Depth and Ego-Motion from Video (CVPR 2017)


- 입력 frames로 부터 Depth CNN과 Pose CNN을 이용해 각각 depth와 pose를 구함
- 구한 pose와 depth를 바탕으로 다른 frame에 픽셀 값을 project해 loss를 구하는 self-supervised 방식
- Non-rigid 객체에 대한 처리를 어떻게 하는지가 관건인데 이것은 Pose CNN이 explainability mask를 같이 구하고 이것으로 non-rigid를 masking하는 것으로 극복
- 대부분의 join depth-(flow)-pose learning 방법들의 시조
- https://arxiv.org/pdf/1704.07813.pdf
- GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose (CVPR 2018)
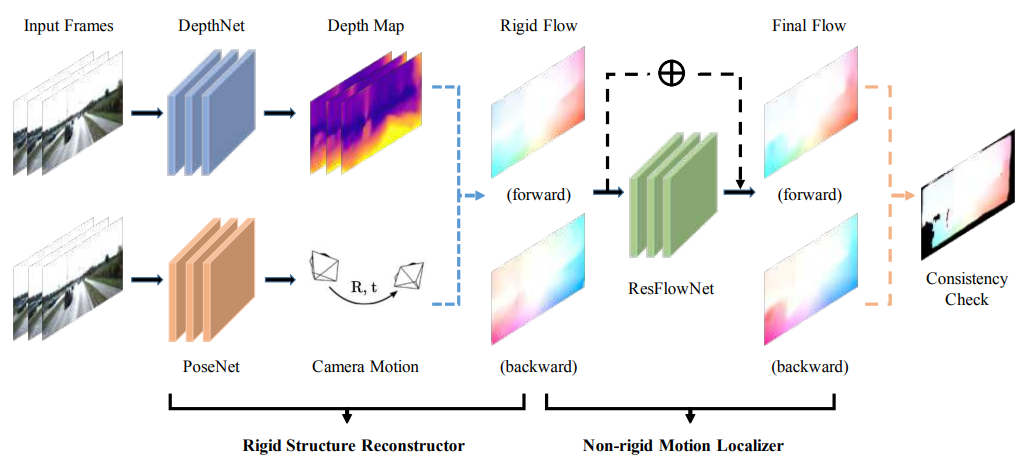
- 입력 frames로 부터 DepthNet과 PoseNet을 이용해 각각 depth와 pose를 구하는 것은 1과 동일
- Depth와 pose를 결합해 frame간 flow를 구하는데 forward 순서, backward 순서 모두 구함
- 이런식으로 구한 flow는 오직 non-rigid object로 인한 문제를 고려하지 않은 것으로 scene rigidity가 보장되어 있다면(dynamic object가 없다면) 두 rigid flow가 방향만 다를 뿐 같은 flow로 볼 수 있지만 그렇지 않으므로 서로 다름
- 이 문제를 해결해 non-rigidity에 대한 flow까지 완벽하게 구할 수 있도록 해주는게 ResFlowNet임
- ResFlowNet은 학습을 통해 두 flow에서 non-rigid object를 인지하고 이에 대한 flow를 조정해줌
- Consistency check는 최종적인 flow에서 rigid한 부분은 방향만 빼고 같아야하는데 그걸 mask해서 비교하는 것으로 볼 수 있음
- 학습은 self-supervised하다고 할 수 있는데 flow나 pose, depth에 대한 G.T.를 사용하지 않고 추정한 flow를 기반으로 warping한 뒤 photo-metric loss를 구하는 방식을 취한다고 할 수 있음
- 1번 방법에서 flow를 구하는게 추가되고 이에 맞춰서 dynamic object를 처리하는 방식도 변경되었다고 볼 수 있음
- https://arxiv.org/pdf/1803.02276.pdf
- DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency (ECCV 2018)

- 2와 유사하지만 flow를 구하기 위한 별도의 네트워크를 내장하고 있는데 이는 네트워크를 두 번 통과해서 flow를 구하는 것 보다 유리해보임
- 따라서 non-rigid를 처리하는 것도 상이함. 그리고 폐색 영역에 대한 mask와 non-rigid를 포함하는 mask가 따로 있는 것 같음?
- DepthNet과 FlowNet을 결합할 수도 있지 않을까?
- 1809.01649.pdf (arxiv.org)
- Digging Into Self-Supervised Monocular Depth Estimation (ICCV 2019)


- 1번 방법에서 occlusion pixel에 대한 matching을 고려한 방식
- 학습 과정에서는 여러 frame은 물론 stereo 영상도 같이 사용하는데 예측된 pose로 projection할 때 각 영상 중 적합한 영상에다가 하는 방식이라 occusion이나 non-rigid 문제를 피할 수 있는 방법인(오른쪽 그림 참고)
- 하지만 flow를 구하지는 못함
- 다만 실제 inference 시에는 하나의 영상만을 사용하기 때문에 depth consistency가 좋다고 할 수 있는지는 의문임(scale이 consistency하도록 최대한 학습이 되기는 하겠지만)
- 1806.01260.pdf (arxiv.org)
- ㅇㅇㅇㅇ
- ㅇㅇㅇ
- ㅇㅇ
댓글